
For many people, the first experience with modern AI was a chat box.
That interface is powerful, but it is not always the most natural way humans communicate.
In many real-world situations, speaking is faster, more expressive, and more convenient than typing. We explain ideas with tone. We interrupt. We pause. We ask follow-up questions. We change direction mid-conversation.
That is why voice agents are becoming an important direction in AI.
A voice agent is not just a chatbot with a microphone. It is a system that can listen, understand, reason, respond, and sometimes take action - through voice, in real time.
The goal of this series is to gradually explore the concepts, technologies, platforms, and practical lessons behind AI voice agents. We will start from the basics, then move into architecture, realtime communication, WebRTC, speech-to-text, text-to-speech, LLMs, open-source frameworks, cloud platforms, and product lessons from building real applications.
What is an AI Voice Agent?
An AI voice agent is a software system that can interact with users through spoken conversation.
At a high level, it can:
- Listen to human speech
- Convert speech into a form the system can understand
- Interpret the user’s intent
- Reason or decide what to do next
- Call tools or business logic when needed
- Generate a response
- Speak the response back to the user
In simple terms:
A voice agent is an AI system that can participate in a spoken conversation and act on the user’s intent.
Most modern voice-agent systems combine several technologies:
- Speech-to-Text (STT / ASR) - Converts spoken audio into text.
- LLM / Agent Brain - Understands intent, reasons, responds, and may call tools.
- Text-to-Speech (TTS) - Converts the agent’s response into spoken audio.
- Realtime Communication Layer - Moves audio between the user and the agent with low latency.
- Application Logic - Connects the agent to real product workflows, data, APIs, and business rules.
Deepgram describes voice agents as systems that combine speech-to-text, text-to-speech, LLM reasoning, and realtime processing. LiveKit similarly defines voice agents as systems that understand speech, think intelligently, and respond with a natural-sounding voice in real time.
It is not only an AI problem. It is also an audio problem, a realtime communication problem, a UX problem, and an infrastructure problem.
Voice Agent vs Chatbot vs Traditional Voice Assistant
It is useful to separate three concepts that are often mixed together.
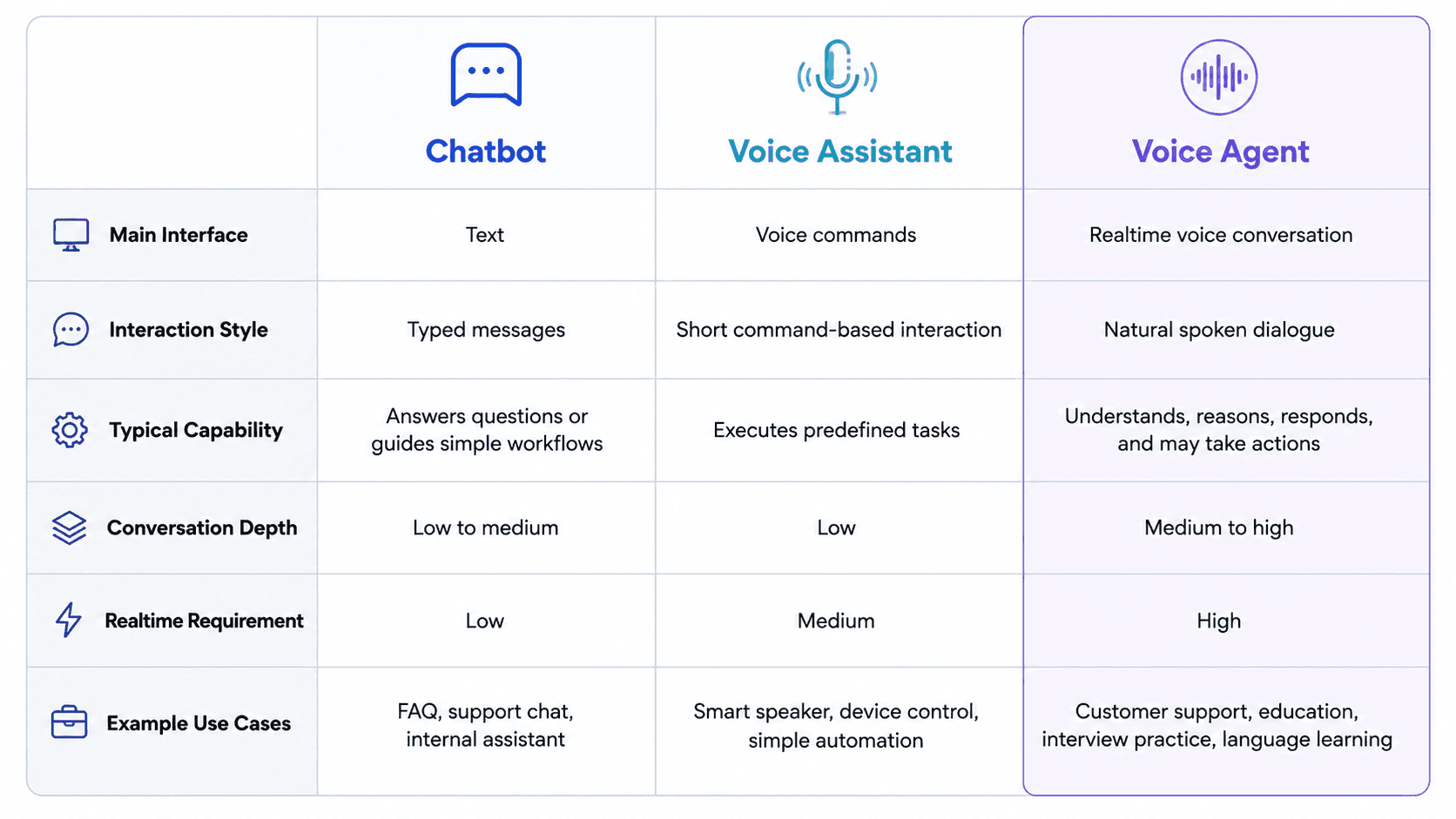
A chatbot usually works through text. The user sends a message, and the system responds.
A traditional voice assistant usually handles command-style interaction. For example: “Set an alarm,” “Play music,” or “Turn off the lights.”
An AI voice agent goes further.
It should be able to handle multi-turn conversation. It may ask clarifying questions. It may remember context. It may call tools. It may perform a workflow. It may adapt based on the user’s answer.
For example, in a mock interview scenario, a voice agent should not only ask a fixed list of questions. It should listen to the candidate’s answer, understand the content, ask follow-up questions, evaluate the response, and provide useful feedback.
In an English speaking practice application, the agent should not only read a script. It should hold a natural conversation, react to the learner’s mistakes, adjust difficulty, and help the user practice speaking with confidence.
This is why voice agents are more complex than they look. The interface is simple: the user just speaks. But behind that simple interface is a chain of realtime systems.
Why Voice Agents Are Becoming Important
Voice agents are becoming more relevant because several technology trends are converging.
LLMs have become much better at understanding language, following instructions, reasoning across multiple turns, and using tools. Speech-to-text and text-to-speech quality have improved significantly. Realtime APIs, streaming infrastructure, and voice-agent frameworks are becoming easier for developers to use.
At the same time, businesses are looking for more natural ways to automate interaction.
Text chat is useful, but many workflows are naturally conversational:
- Customer Support
- Call Centers
- Education
- Language Learning
- Interview Preparation
- Healthcare Intake
- Sales Qualification
- Meeting Assistants
- Accessibility Tools
- Internal Enterprise Assistants
In many cases, users do not want to fill out a form, navigate a dashboard, or type a long message. They want to speak naturally and get help immediately.
That is especially important in use cases where conversation is already part of the workflow:
- A customer calling support
- A student practicing speaking
- A candidate preparing for an interview
- A patient describing symptoms
- A salesperson qualifying a lead
- A team member asking for a meeting summary
Voice agents are interesting because they can make software feel less like a tool and more like a conversation.
Why Voice Is Technically Different From Text
Building a text-based AI application is already challenging. Building a voice agent adds another layer of complexity.
With text, users can tolerate some delay. They type a message, wait a few seconds, and read the answer. With voice, delay is much more noticeable.
If the user says something and the agent responds too slowly, the conversation feels broken. If the agent speaks over the user, it feels annoying. If the agent cannot handle interruptions, it feels unnatural. If the audio quality is poor, users lose trust quickly.
Voice agents need to handle things that text applications often avoid:
- Latency — The delay between user speech and agent response
- Streaming — Processing audio and responses continuously
- Turn Detection — Knowing when the user has finished speaking
- Interruption / Barge-In — Letting the user interrupt the agent naturally
- Audio Quality — Handling noise, echo, packet loss, and unstable networks
- Conversation State — Remembering the context of the conversation
- Tool Use — Calling APIs, databases, or business systems
- Reliability — Handling model, network, and provider failures
OpenAI’s voice-agent documentation highlights this architectural decision clearly: voice agents can be built either as speech-to-speech sessions for natural low-latency conversations, or as chained pipelines where the application explicitly controls speech-to-text, text reasoning, and text-to-speech.
A simple prototype might work with a basic pipeline. But as the product becomes more serious, the engineering decisions become more important.
A Basic Voice Agent Architecture
A simple voice-agent architecture usually looks like this:
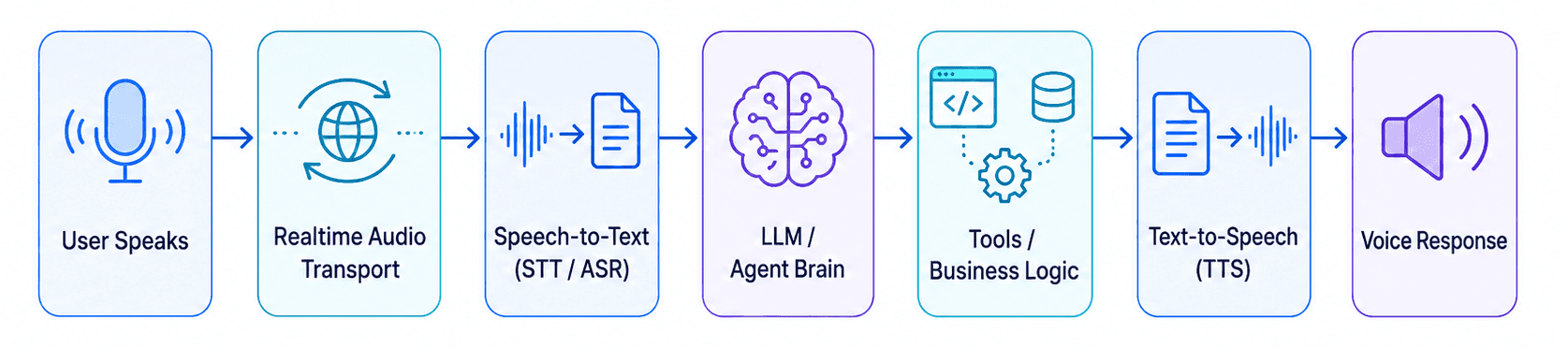
Let’s break this down.
1. User Audio Input
The conversation starts with audio.
The user may speak through:
- A web browser
- A mobile app
- A phone call
- A meeting application
- A smart device
- A classroom or interview interface
The quality of this input matters. Background noise, microphone quality, network conditions, and user behavior can all affect the experience.
2. Realtime Audio Transport
The audio needs to move from the user to the backend or AI system.
This is where technologies like WebRTC, WebSocket, SIP, or telephony media streams may appear.
The transport layer is important because voice is time-sensitive. If audio arrives too late, the agent feels slow. If packets are lost, the transcription quality may suffer. If the system cannot stream bidirectionally, the interaction may feel unnatural.
3. Speech-to-Text
Speech-to-text, also called ASR, converts the user’s speech into text.
This is the input that the LLM or agent system can reason over.
But STT is not only about converting audio into words. In real applications, we also care about:
- Accuracy
- Latency
- Accents
- Noise handling
- Partial transcripts
- Final transcripts
- Speaker identification
- Timestamps
4. LLM / Agent Brain
This is where the system understands the user’s intent and decides what to do.
The LLM may:
- Generate a response
- Ask a follow-up question
- Call a tool
- Search a knowledge base
- Retrieve user data
- Evaluate an answer
- Route the conversation
- Hand off to another workflow
This is why voice agents are often described as “agents,” not just voice bots. The system is not only responding. It may be reasoning, planning, and acting.
5. Tools / Business Logic
For many real products, the agent needs to connect to external systems.
- A customer support agent may check order status.
- An interview practice agent may evaluate a candidate’s answer.
- An education agent may track progress.
- An enterprise assistant may search internal documents.
- A healthcare intake agent may collect structured information before a human review.
This layer is what turns the voice experience from a demo into a product.
6. Text-to-Speech
Once the agent decides what to say, the response needs to become audio again.
Text-to-speech quality matters a lot.
A good TTS system should sound natural, clear, and appropriate for the use case. It should also be fast enough for realtime conversation.
Deepgram describes TTS as more than simply reading text aloud; natural speech also involves prosody, intonation, and stress patterns.
7. Voice Response
Finally, the generated audio is streamed back to the user.
In a good experience, the user should feel like the agent is part of the conversation, not like they are waiting for a batch process to complete.
This is where latency, streaming, and interruption handling become critical.
Why WebRTC Often Appears in Voice-Agent Discussions
When people discuss realtime voice agents, WebRTC often appears quickly.
WebRTC was originally designed for realtime audio, video, and data communication between browsers and devices. It is widely used in video calls, voice calls, live communication tools, and realtime collaboration products.
For voice agents, WebRTC is interesting because it is designed around realtime media. It can help with:
- Low-latency audio streaming
- Bidirectional communication
- Browser and mobile support
- Unstable network conditions
- Realtime media transport
- Interactive conversation experiences
This does not mean WebRTC is always required. Some systems may use WebSockets. Some may use SIP or telephony infrastructure. Some may use provider-specific realtime APIs. The right choice depends on the product. But for browser-based or mobile realtime voice interaction, WebRTC is often a strong fit.
LiveKit’s documentation describes WebRTC as the communication layer between users and agents, while the agent can communicate with backend systems through HTTP and WebSockets. LiveKit also notes that its Agents SDK handles realtime voice AI challenges such as STT-LLM-TTS pipelines, turn detection, interruptions, and orchestration.
Cloudflare’s RealtimeKit is also built on WebRTC infrastructure and is designed to add live video and voice to web and mobile applications.
We will go deeper into WebRTC, WebSocket, SIP, and realtime communication tradeoffs in a later article.
Cloud and Open-Source Platforms Are Emerging
Another reason voice agents are becoming more practical is that the ecosystem is growing quickly.
A few years ago, building a realtime AI voice agent often required stitching together many pieces manually. Today, we are seeing both open-source frameworks and cloud platforms focused on this space. Some examples include:
Open-Source / Developer Frameworks
- LiveKit Agents
- Pipecat
- LangGraph or other orchestration tools when combined with voice infrastructure
Cloud / Managed Platforms
- OpenAI Realtime API / Voice Agents
- LiveKit Cloud
- Cloudflare RealtimeKit
- Deepgram Voice Agent / STT / TTS ecosystem
- Twilio Voice + Media Streams
- Daily
In later articles, we will explore these tools more deeply.
Why We Care About Voice Agents at ZamoTech
At ZamoTech, we are exploring voice agents in education and skill development. Two products we are currently building are:
AI Mock Interview
KoffiTalk
AI Mock Interview focuses on helping users practice interview conversations with AI.
KoffiTalk focuses on helping users practice English speaking skills by talking with AI.
In interview practice, users need to speak clearly, organize thoughts, respond under pressure, and improve through feedback.
In English speaking practice, users need repetition, confidence, correction, natural conversation, and a low-pressure environment to practice. Typing alone cannot fully simulate those experiences.
A good voice agent can make practice feel more natural. It can help users speak, listen, respond, and improve through repeated realtime interaction.
This is why we are interested in voice agents not only as a technology trend, but as a product direction.
What This Series Will Explore
This article is only the starting point.
In the following posts, we will gradually explore the voice-agent space from both technical and product perspectives.
References
- Deepgram — What Exactly Is an AI Voice Agent?
- LiveKit — Voice Agents
- LiveKit Documentation — Agents Framework Introduction
- OpenAI — Voice Agents Guide
- Cloudflare — RealtimeKit Documentation
- Pipecat — Realtime Voice & Multimodal AI Agents
- a16z — AI Voice Agents: 2025 Update